Computer Science and Artificial Intelligence
Clustering is a fundamental technique for grouping a collection of elements/units according to their characteristics in order to obtain groups, called clusters, that are homogeneous within them and well separated from each other group, as in the well-known K-Means heuristic. This research focuses on the theoretical and algorithmic study of clustering problems with cardinality constraints, in which each cluster must contain a well-established number of elements. The study analyzes computational complexity and algorithms for variants of the problem with different Lp metrics in low-dimensional spaces and with relaxation of constraints.
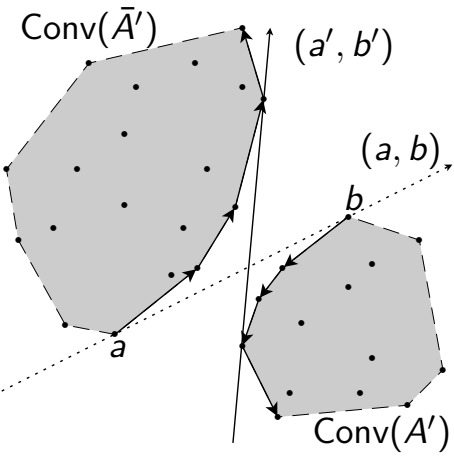
Initial analyses reveal geometric separation properties and exchange conditions between clusters that characterize optimal solutions. The problems examined are computationally difficult in many parametric configurations, even in the case of bipartition in dimension one. Nevertheless, studies have produced efficient exact algorithms, also by dynamic programming, for certain subclasses of problems, exploiting combinatorial and algebraic geometry tools such as k-set and CAD, as well as dynamic data structures, such as adapted balanced trees.
These results contribute to the study of balanced clustering, highlighting computational limitations and providing optimal solutions, with repercussions on applications in different areas, such as load balancing, market segmentation, data compression and balanced resource allocation.
Keywords and topics covered:
Constrained clustering, Cardinality constraints, Computational complexity, Exact algorithms, Euclidean norm, Manhattan norm, k-set, Discrete optimization, Polynomial algorithms
People involved:
![]()
Sparse representations are based on the principle of parsimony and are one of the fundamental techniques in machine learning to compress and control the complexity of models. This line of research explores methods and algorithms for sparse decomposition, applied to different fields such as signal processing, computer vision, machine learning and data analysis.
The techniques developed include smooth optimization algorithms examined from the point of view of convergence and optimality, sparse decomposition for learning overcomplete dictionaries by orthogonal Procrustes analysis and maximum likelihood estimates regularized in sparse logistic models.
The results indicate that sparse models outperform classical methods in terms of accuracy, robustness, and interpretability, especially in the presence of high-dimensional and structurally redundant data. The contributions are relevant for applications in the domains of bioinformatics, biomedical imaging, natural language processing, and social sciences.
Keywords and topics covered:
Sparse decomposition, sparse regression, 0-norm, non-convex optimisation, sparse dictionary learning, signal compression, phase transition, Procrustes analysis, parsimony principle
People involved:

In the field of Computer Vision, the development of reliable and scalable automatic systems for the visual recognition of people, objects, scenes and individual visual signs in difficult or extreme real conditions, often characterized by variations in terms of lighting, orientation, deformations, occlusions, expressions or poor availability and quality of data, assumes central importance. The study of the problems of automatic recognition of people and objects is also motivated by the growing relevance of cybersecurity technologies for the protection of strategic digital assets and ecosystems for an organization.
Modern AI systems integrate Deep Learning models prepared on massive datasets with traditional Machine Learning methods, such as sparse representation and coding with discriminating capacity, also through transfer learning techniques, aiming to recognize objects and people in the presence of a few or a single sample per class, or in few-shot or one-shot learning scenarios. A significant extension concerns the modeling of the somatic motor space for the analysis of affective facial expressions, allowing human-machine interactions more sensitive to the emotional context. In addition, mechanisms have been introduced for the estimation of the degree of reliability for each recognition produced, in order to improve the interpretability of the system.
The impact of this research extends to so-called phygital or cyberphysical contexts such as assistive technologies for the person, user interfaces and emotion-aware social platforms, biometric recognition, where reliability and adaptability of the system are required in varied and difficult operating conditions.
Keywords and topics covered:
Image Recognition, Sparse Representation, Deep Learning Features, Few-shot and One-shot Learning, Discriminant Analysis, Affective Computing, Large-Scale Biometrics, Identity Confidence
People involved: