Informatica e intelligenza artificiale
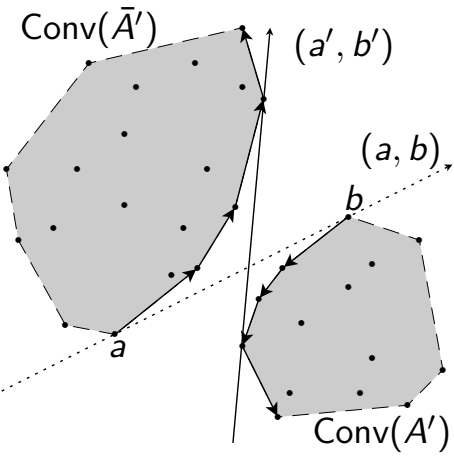
Il clustering è una tecnica fondamentale per raggruppare una collezione di elementi/unità in base alle loro caratteristiche in modo tale da ottenere dei gruppi, chiamati cluster, che siano omogenei al loro interno e ben separati da ciascun altro gruppo, come nella nota euristica K-Means. Questa ricerca si concentra sullo studio teorico e algoritmico di problemi di clustering con vincoli di cardinalità, in cui ogni cluster deve contenere un numero di elementi ben stabilito. Lo studio analizza la complessità computazionale e gli algoritmi per varianti del problema con diverse metriche Lp in spazi a bassa dimensione e con rilassamento dei vincoli.
Dalle analisi iniziali emergono proprietà di separazione geometrica e condizioni di scambio tra cluster che caratterizzano le soluzioni ottimali. I problemi esaminati risultano computazionalmente difficili in molte configurazioni parametriche, anche in caso di bipartizione in dimensione uno. Ciononostante gli studi hanno prodotto algoritmi esatti efficienti, anche mediante programmazione dinamica, per certe sottoclassi di problemi, sfruttando strumenti di geometria combinatoria e algebrica come k-set e CAD, oltre a strutture dati dinamiche, quali alberi bilanciati adattati.
Questi risultati contribuiscono allo studio del clustering bilanciato, evidenziando limiti computazionali e fornendo soluzioni ottimali, con ricadute su applicazioni in diversi ambiti, come il bilanciamento del carico, la segmentazione di mercato, la compressione dei dati e l'allocazione equilibrata di risorse.
Parole chiave e temi trattati:
Clustering vincolato, Vincoli di cardinalità, Complessità computazionale, Algoritmi esatti, Norma Euclidea, Norma di Manhattan, k-set, Ottimizzazione discreta, Algoritmi polinomiali
Persone coinvolte:
![]()
Le rappresentazioni sparse si basano sul principio di parsimonia e costituiscono una delle tecniche fondamentali nel machine learning per comprimere e tenere sotto controllo la complessità dei modelli. Questa linea di ricerca esplora metodi e algoritmi per la decomposizione sparsa, applicati a diversi campi quali l'elaborazione dei segnali, la visione artificiale, l'apprendimento automatico e l’analisi dei dati.
Le tecniche sviluppate includono algoritmi di ottimizzazione smooth esaminati dal punto di vista di convergenza e ottimalità, decomposizione sparsa per l'apprendimento di dizionari sovracompleti tramite analisi di Procrustes ortogonale e stime di massima verosimiglianza regolarizzate in modelli logistici sparsi.
I risultati indicano che i modelli sparsi superano i metodi classici in termini di accuratezza, robustezza e interpretabilità, soprattutto in presenza di dati ad alta dimensionalità e strutturalmente ridondanti. I contributi sono rilevanti per le applicazioni nei domini della bioinformatica, del biomedical imaging, dell’elaborazione del linguaggio naturale e delle scienze sociali.
Parole chiave e temi trattati:
Decomposizione sparsa, regressione sparsa, 0-norm, ottimizzazione non convessa, sparse dictionary learning, compressione di segnali, transizione di fase, analisi di Procrustes, principio di parsimonia
Persone coinvolte:
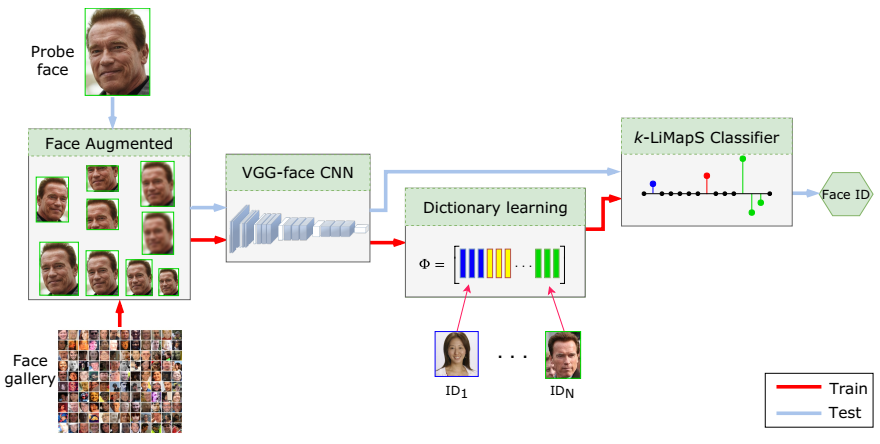
Nell'ambito della Visione Artificiale assume un'importanza centrale lo sviluppo di sistemi automatici affidabili e scalabili per il riconoscimento visuale di persone, oggetti, scene e singoli segni visivi in condizioni reali difficili o estreme, spesso caratterizzate da variazioni in termini di illuminazione, orientamento, deformazioni, occlusioni, espressioni o scarsa disponibilità e qualità dei dati. Lo studio dei problemi di riconoscimento automatico di persone e oggetti è inoltre motivato dalla crescente rilevanza delle tecnologie di cybersicurezza per la protezione di asset ed ecosistemi digitali strategici per un'organizzazione.
I sistemi AI moderni integrano modelli di Deep Learning predisposti su dataset massivi con metodi di Machine Learning tradizionali, come la rappresentazione e codifica sparsa con capacità discriminante, anche mediante tecniche di transfer learning, mirando a riconoscere oggetti e persone in presenza di pochi o un singolo campione per classe, ovvero in scenari di few-shot o one-shot learning. Un’estensione significativa riguarda la modellazione dello spazio motorio somatico per l’analisi delle espressioni facciali affettive, permettendo interazioni uomo-macchina più sensibili al contesto emozionale. Inoltre, sono stati introdotti meccanismi per la stima del grado di affidabilità per ogni riconoscimento prodotto, in modo da migliorare l’interpretabilità del sistema.
L’impatto di questa ricerca si estende a contesti cosiddetti phygital o cyberphysical quali le tecnologie assistive per la persona, le interfacce utente e le piattaforme social emotion-aware, il riconoscimento biometrico, dove sono richieste affidabilità e adattabilità del sistema in condizioni operative variegate difficili.
Parole chiave e temi trattati:
Image Recognition, Sparse Representation, Deep Learning Features, Few-shot and One-shot Learning, Discriminant Analysis, Affective Computing, Large-Scale Biometrics, Identity Confidence
Persone coinvolte: